

Part 16. RISC-V Vector Extension

content by Xing Chen
I asked the following question in Part 12: “Why should we re-invent the SIMD instead of directly deploy the vector floating-point functional units, plus the vector registers, pioneered by Mr. Cray, onto a modern CPU chip?”
It is simply not possible to integrate (merge) the Cray style vector pipeline(s) into modern superscalar CPUs, like X86 or ARM, because there are too many architectural differences between the two, among all the others, the main ones that I saw are the following, stemmed from their different design philosophies: The traditional vector processors are designed to exploit data parallelism, while modern superscalar CPUs are designed to squeeze instruction level parallelism (they invented SIMD to move to data parallelism)!
1. The traditional vector processors had very long vector registers, for example, the Cray-1 had multiple 64-element registers, each element was 64bits, that made a register was as long as 4096 bits, while we know X86 AVX-512 has only 512-bit registers (as its name has shown), not even to mention the 256-element long vector registers (256×64 bits) of NEC Vector Engine.
2. To keep the vector pipeline busy, the traditional vector processor machines needed very high memory bandwidth and did not use cache (only very late we saw cache appear on the vector processors), it is quite different than the modern superscalar CPUs, which, always have multiple levels of cache (L1/2/3) to deal with data temporal and spatial locality, thus reduce their demand for memory bandwidth.
To keep the traditional vector processing technology live and even integrate/merge with modern superscalar CPUs, requires rethinking their design and adapting each other. I’m so happy to see there are people like me who don’t want the traditional vector processing technology to die, at lease, for “Archio Diversity” sake, and would like to make it great again! 😉
As one example, probably the most promising one, RISC-V had published its vector extension and evolved to version 1.0. https://riscv.org/
The RISC-V Vector Extension followed similar principles as the early day Cray vector processors, so is a kind of Cray-like vector extension but integrated into a modern superscalar CPU, hereunder one of its commercialization, from the Andes Technology.
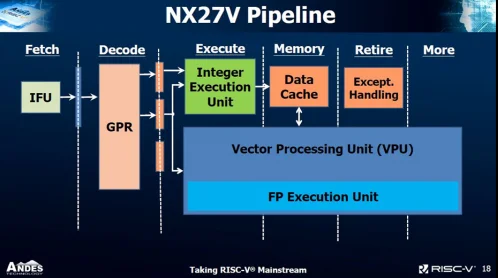
“The NX27V contains a vector processing unit (VPU) which supports the RVV scalable vector instruction set, designed from the ground up to be a Cray-like full vectorization computation unit” from Andes’ Core has RISC-V Vector Instruction Extension — EE Times
If you like, it is suggested to follow the evolution of the integration of this kind of Cray-like vector processing units into modern superscalar CPUs, this can be a game changer to the industry, by competing with, or replacing SIMD and even SIMT (=Nvidia GPU). Seriously!





