Part 15. Bad Luck for Vector Engine

content by Xing Chen
Started from 2006, ended by 2012, the Japaness “Next-Generation Supercomputer Project”, lasted for 7 years and led to the inauguration of the famous K Computer.
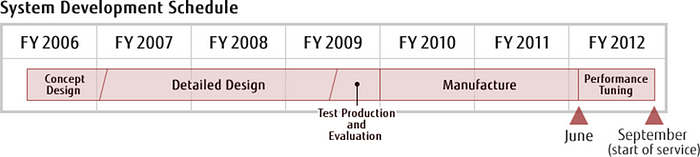
“The original plan (of the project) was to have Fujitsu donate Sparc64 scalar processors to the cause and mix them with NEC SX vector engines with a sophisticated torus interconnect created by Hitachi to bring them all together into a single system.” Cited from the following link: https://www.nextplatform.com/2017/10/26/can-vector-supercomputing-revived/
“NEC this morning announced in Tokyo that it was pulling out of the Next Generation Supercomputer Project sponsored by the Japanese government. The project involved NEC, Fujitsu, and Hitachi building a hybrid scalar/vector massively parallel system.” From the following report dated 14/May/2009: https://www.theregister.com/2009/05/14/nec_pulls_out_of_keisoku/
“(After had withdrawn from the project,) Hitachi donated the interconnect to Fujitsu, which we now know as the Tofu interconnect at the heart of the K supercomputer at RIKEN, the first machine to break the 10 petaflops barrier.” Cited from the following link: https://www.nextplatform.com/2017/10/26/can-vector-supercomputing-revived/
November 2011, K Computer became the first computer to top 10 petaflops, and №1 on Top500.
“Had NEC stayed in the Keisuko project, then Fujitsu and NEC would have no doubt created a hybrid architecture using a mix of scalar and vector processors, with the vast majority of the compute coming from the vector engines made by NEC. They would have created an offload model similar to that espoused by Nvidia with its GPU accelerators, and NEC would quite possibly have made a considerable amount more money with its SX systems. And it would have been part of the Fugaku system and very likely part of the Fugaku-Next system. In short: NEC could not reap what it was not willing to sow, and Fujitsu has done a good job demonstrating how ease of programming and making a vector-heavy hybrid scalar/vector compute engine is more elegant and efficient (given the right interconnect, of course) than having hybrid CPU and GPU combinations within a node and using InfiniBand to link nodes together.” Taken from the following link: https://www.nextplatform.com/2023/03/23/is-this-the-end-of-the-line-for-nec-vector-supercomputers/
Well, the real history is indeed sometimes more fictive than a fiction! I have nothing to say! Now the remaining question is the following:
“Is This (Vector Engine) The End Of The Line For NEC Vector Supercomputers?” https://www.nextplatform.com/2023/03/23/is-this-the-end-of-the-line-for-nec-vector-supercomputers/